FastAPI ASGI on Modal for OpenAI Throughput
Intro
In this post I show how easy it is to scale OpenAI throughput with a FastAPI web service on Modal.
To keep this concrete, I use one task throughout this post: topic classification for Hacker News titles. I benchmark four setups:
- single-host thread pool (sync client)
- single-host vanilla asyncio with
AsyncOpenAI - single-host asyncio with sharded clients/connection pools
- an auto-scaling ASGI
FastAPIservice on Modal
All approaches use the same prompt/model and the same title dataset. This is intentionally a demo, not production architecture. The goal is minimal code and clear comparisons you can reproduce quickly.

Approach 1: Single-Host Thread Pool
This baseline uses the sync OpenAI client and ThreadPoolExecutor on one machine.
It is simple and works well enough as a control before moving to async and then multi-container ASGI.
from dotenv import load_dotenv
# load in the OpenAI API key
load_dotenv("posts/modal_asgi_openai/.env")
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
from typing import Literal
import time
from IPython.display import HTML, display
from openai import OpenAI
from pydantic import BaseModel, Field
OPENAI_MODEL = "gpt-4.1-mini"
OPENAI_TIMEOUT_S = 20
TOPIC_PROMPT = """Classify one Hacker News title into a topic label.
topic:
- ai_ml_agents
- programming_dev_tools
- infra_cloud_ops
- hardware_electronics
- security_privacy
- business_startups_career
- science_math_research
- society_policy_economy
- culture_media_games
- other
Return only fields in the schema.
confidence is a float from 0.0 to 1.0.
"""
Topic = Literal[
"ai_ml_agents",
"programming_dev_tools",
"infra_cloud_ops",
"hardware_electronics",
"security_privacy",
"business_startups_career",
"science_math_research",
"society_policy_economy",
"culture_media_games",
"other",
]
class TopicClassification(BaseModel):
topic: Topic
confidence: float = Field(ge=0.0, le=1.0)
def show_df(df):
display(HTML(df.to_html(index=False)))
DATA_PATH = Path("posts/modal_asgi_openai/data/hn_recent_story_titles_1000.txt")
titles = [line.strip() for line in DATA_PATH.read_text(encoding="utf-8").splitlines() if line.strip()]
def classify_one_sync(client: OpenAI, title: str) -> TopicClassification:
response = client.responses.parse(
model=OPENAI_MODEL,
instructions=TOPIC_PROMPT,
input=[{"role": "user", "content": title}],
text_format=TopicClassification,
timeout=OPENAI_TIMEOUT_S,
)
return response.output_parsed
def run_threadpool(titles: list[str], max_workers: int = 40) -> dict:
if max_workers < 1:
raise ValueError("max_workers must be >= 1")
t0 = time.perf_counter()
results: list[TopicClassification | Exception] = [None] * len(titles)
client = OpenAI()
try:
with ThreadPoolExecutor(max_workers=max_workers) as ex:
fut_to_idx = {ex.submit(classify_one_sync, client, title): i for i, title in enumerate(titles)}
for fut in as_completed(fut_to_idx):
idx = fut_to_idx[fut]
try:
results[idx] = fut.result()
except Exception as exc: # demo notebook
results[idx] = exc
finally:
client.close()
elapsed = time.perf_counter() - t0
errors = sum(isinstance(x, Exception) for x in results)
return {
"num_items": len(titles),
"max_workers": max_workers,
"concurrency": max_workers,
"elapsed_s": round(elapsed, 2),
"req_per_s": round(len(titles) / elapsed, 1),
"errors": errors,
"results": results,
}
bench_1 = run_threadpool(titles, max_workers=40)
{k: bench_1[k] for k in ["num_items", "max_workers", "elapsed_s", "req_per_s", "errors"]}
import pandas as pd
WORKER_SWEEP = [10, 20, 40, 80, 120]
NUM_ITEMS = len(titles) # lower this for quick/cheap runs
sweep_titles = titles[:NUM_ITEMS]
sweep_rows = []
for w in WORKER_SWEEP:
row = run_threadpool(sweep_titles, max_workers=w)
row.pop("results", None)
sweep_rows.append(row)
sweep_df = pd.DataFrame(sweep_rows)
show_df(sweep_df)
from pathlib import Path
from datetime import datetime, timezone
OUT_PATH = Path("posts/modal_asgi_openai/data/threadpool_worker_sweep.csv")
run_df = sweep_df.assign(ran_at_utc=datetime.now(timezone.utc).isoformat())
if OUT_PATH.exists():
run_df = pd.concat([pd.read_csv(OUT_PATH), run_df], ignore_index=True)
run_df.to_csv(OUT_PATH, index=False)
OUT_PATH
Approach 2: Single-Host Vanilla Async
This uses the same async classification pattern as we see in modal_service.py (later in this post), but runs locally on one host. The only tuning knob here is concurrency (semaphore size).
import asyncio
from openai import AsyncOpenAI
async def run_vanilla_async(titles: list[str], concurrency: int = 50) -> dict:
if concurrency < 1:
raise ValueError("concurrency must be >= 1")
t0 = time.perf_counter()
client = AsyncOpenAI()
try:
sem = asyncio.Semaphore(min(concurrency, len(titles)))
async def classify_one(title: str) -> TopicClassification:
async with sem:
response = await client.responses.parse(
model=OPENAI_MODEL,
instructions=TOPIC_PROMPT,
input=[{"role": "user", "content": title}],
text_format=TopicClassification,
timeout=OPENAI_TIMEOUT_S,
)
return response.output_parsed
raw_results = await asyncio.gather(
*(classify_one(title=t) for t in titles),
return_exceptions=True,
)
results = []
errors = 0
for item in raw_results:
if isinstance(item, Exception):
errors += 1
results.append({"topic": None, "confidence": None, "error": str(item)})
else:
results.append(
{
"topic": item.topic,
"confidence": item.confidence,
"error": None,
}
)
finally:
await client.close()
elapsed = time.perf_counter() - t0
return {
"num_items": len(titles),
"concurrency": concurrency,
"elapsed_s": round(elapsed, 2),
"req_per_s": round(len(titles) / elapsed, 1),
"errors": errors,
"results": results,
}
bench_2 = await run_vanilla_async(titles, concurrency=50)
{k: bench_2[k] for k in ["num_items", "concurrency", "elapsed_s", "req_per_s", "errors"]}
import pandas as pd
ASYNC_CONCURRENCY_SWEEP = [10, 20, 40, 80, 120, 240]
NUM_ITEMS = len(titles) # lower this for quick/cheap runs
sweep_titles = titles[:NUM_ITEMS]
async_rows = []
for c in ASYNC_CONCURRENCY_SWEEP:
row = await run_vanilla_async(sweep_titles, concurrency=c)
row.pop("results", None)
async_rows.append(row)
async_df = pd.DataFrame(async_rows)
show_df(async_df)
from pathlib import Path
from datetime import datetime, timezone
OUT_PATH = Path("posts/modal_asgi_openai/data/vanilla_async_concurrency_sweep.csv")
run_df = async_df.assign(ran_at_utc=datetime.now(timezone.utc).isoformat())
if OUT_PATH.exists():
run_df = pd.concat([pd.read_csv(OUT_PATH), run_df], ignore_index=True)
run_df.to_csv(OUT_PATH, index=False)
OUT_PATH
Approach 2b: Single-Host Async + Client Shards
This keeps everything on one machine, but splits load across multiple AsyncOpenAI clients and HTTP/2 connection pools.
The point is to test whether a single host can push much closer to provider limits before moving to multi-container infrastructure.
import httpx
from openai import AsyncOpenAI
def _split_concurrency(total_concurrency: int, client_shards: int) -> list[int]:
shard_count = min(total_concurrency, client_shards)
base, extra = divmod(total_concurrency, shard_count)
return [base + (1 if i < extra else 0) for i in range(shard_count)]
async def run_sharded_async(
titles: list[str],
total_concurrency: int = 240,
client_shards: int = 16,
) -> dict:
t0 = time.perf_counter()
shard_sizes = _split_concurrency(total_concurrency, client_shards)
clients = []
semaphores = []
for shard_concurrency in shard_sizes:
http_client = httpx.AsyncClient(
http2=True,
limits=httpx.Limits(
max_connections=shard_concurrency,
max_keepalive_connections=shard_concurrency,
),
)
clients.append(AsyncOpenAI(http_client=http_client, max_retries=0))
semaphores.append(asyncio.Semaphore(shard_concurrency))
async def classify_one(i: int, title: str) -> TopicClassification:
shard = i % len(clients)
async with semaphores[shard]:
response = await clients[shard].responses.parse(
model=OPENAI_MODEL,
instructions=TOPIC_PROMPT,
input=[{"role": "user", "content": title}],
text_format=TopicClassification,
timeout=OPENAI_TIMEOUT_S,
)
return response.output_parsed
try:
raw_results = await asyncio.gather(
*(classify_one(i=i, title=t) for i, t in enumerate(titles)),
return_exceptions=True,
)
finally:
await asyncio.gather(*(client.close() for client in clients))
results = []
errors = 0
for item in raw_results:
if isinstance(item, Exception):
errors += 1
results.append({"topic": None, "confidence": None, "error": str(item)})
else:
results.append(
{
"topic": item.topic,
"confidence": item.confidence,
"error": None,
}
)
elapsed = time.perf_counter() - t0
return {
"num_items": len(titles),
"total_concurrency": total_concurrency,
"client_shards": client_shards,
"elapsed_s": round(elapsed, 2),
"req_per_s": round(len(titles) / elapsed, 1),
"errors": errors,
"results": results,
}
bench_2b = await run_sharded_async(titles * 3, total_concurrency=400, client_shards=16)
{k: bench_2b[k] for k in ["num_items", "total_concurrency", "client_shards", "elapsed_s", "req_per_s", "errors"]}
import pandas as pd
SHARDED_CONCURRENCY_SWEEP = [120, 240, 360, 480, 600]
CLIENT_SHARDS = 16
NUM_ITEMS = len(titles) * 3
sweep_titles = (titles * 3)[:NUM_ITEMS]
sharded_rows = []
for c in SHARDED_CONCURRENCY_SWEEP:
row = await run_sharded_async(
sweep_titles,
total_concurrency=c,
client_shards=CLIENT_SHARDS,
)
row.pop("results", None)
sharded_rows.append(row)
sharded_df = pd.DataFrame(sharded_rows)
show_df(sharded_df)
from pathlib import Path
from datetime import datetime, timezone
OUT_PATH = Path("posts/modal_asgi_openai/data/sharded_async_concurrency_sweep.csv")
run_df = sharded_df.assign(ran_at_utc=datetime.now(timezone.utc).isoformat())
if OUT_PATH.exists():
run_df = pd.concat([pd.read_csv(OUT_PATH), run_df], ignore_index=True)
run_df.to_csv(OUT_PATH, index=False)
OUT_PATH
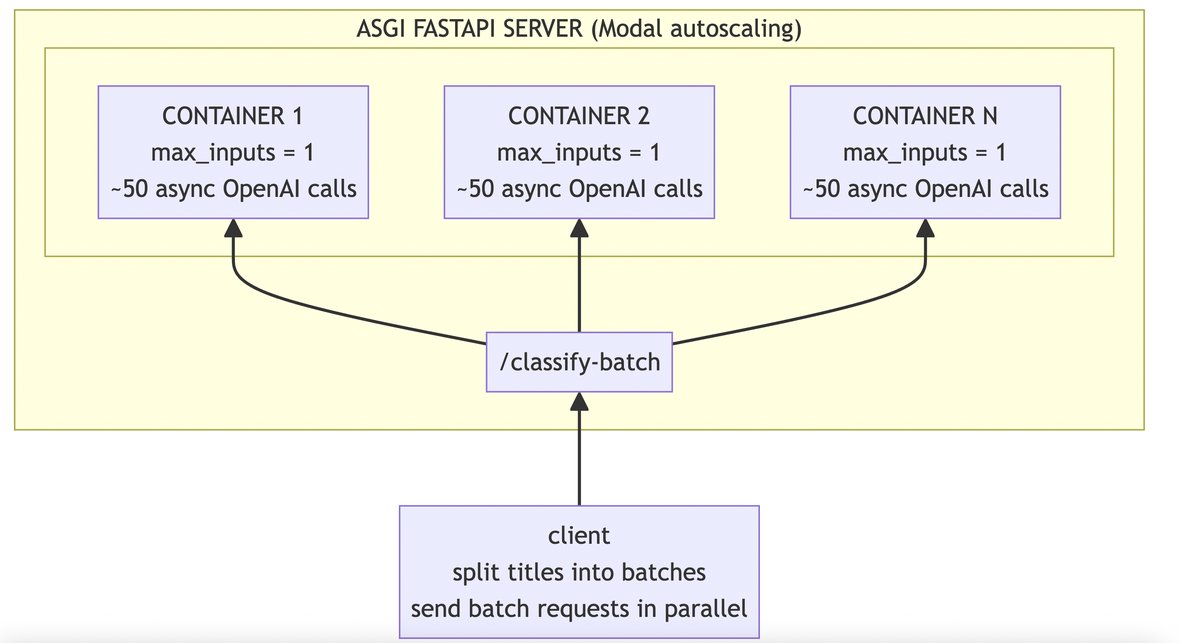
Approach 3: Auto-Scaling ASGI on Modal
For the final approach, we keep the same async classification pattern but move it behind a FastAPI ASGI endpoint on Modal.
The request handler in posts/modal_asgi_openai/modal_service.py uses the same semaphore + asyncio.gather(..., return_exceptions=True) flow as the single-host async approaches.
The difference is where concurrency comes from:
- per-request OpenAI concurrency via
OPENAI_WORKERS_PER_REQUEST- this is the concurrency within the handler of the FastAPI endpoint for handling a single request/batch
- per-container request concurrency via
MAX_INPUTS- how many http requests/batches a single container can handle in parallel
- horizontal scale via Modal
max_containers
Deploy:
uv run --no-project --with modal --with python-dotenv modal deploy posts/modal_asgi_openai/modal_service.py
Call:
curl -X POST "https://drchrislevy--hn-title-classifier-api.modal.run/classify-batch" \
-H "content-type: application/json" \
-d '{"titles":["Show HN: Turn LinkedIn profiles into Markdown for LLM use"]}'
- Note: this comparison includes network and platform overhead.
- The single-host approaches isolate local runtime behavior; Modal adds scale-out behavior.
Benchmarking the Modal Endpoint
For this approach, the client splits titles into batches and fans requests out in parallel.
We set request_concurrency = ceil(num_items / batch_size) so batches are sent in one wave.
Batch size defaults to 20 for smaller runs and 50 once num_items > 1000.
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
MODAL_ENDPOINT = "https://drchrislevy--hn-title-classifier-api.modal.run/classify-batch"
def _post_modal_batch(batch: list[str], timeout_s: int) -> dict:
resp = requests.post(
MODAL_ENDPOINT,
json={"titles": batch},
timeout=timeout_s,
)
resp.raise_for_status()
return resp.json()
def run_modal_endpoint(
titles: list[str],
batch_size: int | None = None,
timeout_s: int = 300,
) -> dict:
if batch_size is None:
batch_size = 50 if len(titles) > 1000 else 20
if batch_size < 1:
raise ValueError("batch_size must be >= 1")
batches = [
(start, titles[start : start + batch_size])
for start in range(0, len(titles), batch_size)
]
num_batches = len(batches)
request_concurrency = max(1, num_batches)
results = [None] * len(titles)
errors = 0
t0 = time.perf_counter()
if batches:
with ThreadPoolExecutor(max_workers=request_concurrency) as ex:
fut_to_meta = {
ex.submit(_post_modal_batch, batch, timeout_s): (start, len(batch))
for start, batch in batches
}
for fut in as_completed(fut_to_meta):
start, size = fut_to_meta[fut]
end = start + size
try:
payload = fut.result()
except Exception as exc: # demo notebook
errors += size
results[start:end] = [
{"topic": None, "confidence": None, "error": str(exc)}
] * size
continue
batch_results = payload["results"]
results[start:end] = batch_results
errors += int(payload["errors"])
elapsed = time.perf_counter() - t0
return {
"num_items": len(titles),
"batch_size": batch_size,
"num_batches": num_batches,
"request_concurrency": request_concurrency,
"elapsed_s": round(elapsed, 2),
"req_per_s": round(len(titles) / elapsed, 1) if titles else 0.0,
"errors": errors,
"results": results,
}
bench_3 = run_modal_endpoint(titles*3, batch_size=None)
{k: bench_3[k] for k in ["num_items", "batch_size", "num_batches", "request_concurrency", "elapsed_s", "req_per_s", "errors"]}
from pathlib import Path
from datetime import datetime, timezone
OUT_PATH = Path("posts/modal_asgi_openai/data/modal_endpoint_run.csv")
row = {k: v for k, v in bench_3.items() if k != "results"}
run_df = pd.DataFrame([row]).assign(ran_at_utc=datetime.now(timezone.utc).isoformat())
if OUT_PATH.exists():
run_df = pd.concat([pd.read_csv(OUT_PATH), run_df], ignore_index=True)
run_df.to_csv(OUT_PATH, index=False)
OUT_PATH
Key Code: ASGI FastAPI on Modal
This is the implementation worth paying attention to in this post.
It is a minimal FastAPI ASGI service deployed on Modal, with:
- async OpenAI calls inside each request handler
- bounded in-handler concurrency via a semaphore
asyncio.gather(..., return_exceptions=True)for batch fan-out- horizontal autoscaling handled by Modal
This is the exact code used for Approach 3:
from pathlib import Path
from IPython.display import Markdown, display
service_path = Path("posts/modal_asgi_openai/modal_service.py")
service_code = service_path.read_text(encoding="utf-8")
display(Markdown(f"```python\n{service_code}\n```"))
Combined Benchmark Summary
The CSVs are append-only, so each run is preserved. This cell picks the best req_per_s row per approach and writes benchmark_summary.csv.
For fair comparisons, match num_items across approaches (for example, compare 3000 vs 3000).
from pathlib import Path
import pandas as pd
DATA_DIR = Path("posts/modal_asgi_openai/data")
thread_df = pd.read_csv(DATA_DIR / "threadpool_worker_sweep.csv")
async_df = pd.read_csv(DATA_DIR / "vanilla_async_concurrency_sweep.csv")
sharded_df = pd.read_csv(DATA_DIR / "sharded_async_concurrency_sweep.csv")
modal_df = pd.read_csv(DATA_DIR / "modal_endpoint_run.csv")
thread_best = thread_df.loc[thread_df["req_per_s"].idxmax()]
async_best = async_df.loc[async_df["req_per_s"].idxmax()]
sharded_best = sharded_df.loc[sharded_df["req_per_s"].idxmax()]
modal_best = modal_df.loc[modal_df["req_per_s"].idxmax()]
summary_df = pd.DataFrame(
[
{
"approach": "threadpool_single_host",
"setting": f"workers={int(thread_best['max_workers'])}",
"num_items": int(thread_best["num_items"]),
"best_req_per_s": float(thread_best["req_per_s"]),
"elapsed_s": float(thread_best["elapsed_s"]),
"errors": int(thread_best["errors"]),
"num_runs": int(len(thread_df)),
"ran_at_utc": thread_best["ran_at_utc"],
},
{
"approach": "asyncio_single_host",
"setting": f"concurrency={int(async_best['concurrency'])}",
"num_items": int(async_best["num_items"]),
"best_req_per_s": float(async_best["req_per_s"]),
"elapsed_s": float(async_best["elapsed_s"]),
"errors": int(async_best["errors"]),
"num_runs": int(len(async_df)),
"ran_at_utc": async_best["ran_at_utc"],
},
{
"approach": "asyncio_sharded_single_host",
"setting": (
f"concurrency={int(sharded_best['total_concurrency'])}, "
f"shards={int(sharded_best['client_shards'])}"
),
"num_items": int(sharded_best["num_items"]),
"best_req_per_s": float(sharded_best["req_per_s"]),
"elapsed_s": float(sharded_best["elapsed_s"]),
"errors": int(sharded_best["errors"]),
"num_runs": int(len(sharded_df)),
"ran_at_utc": sharded_best["ran_at_utc"],
},
{
"approach": "modal_asgi_autoscale",
"setting": (
f"batch_size={int(modal_best['batch_size'])}, "
f"requests={int(modal_best['request_concurrency'])}"
),
"num_items": int(modal_best["num_items"]),
"best_req_per_s": float(modal_best["req_per_s"]),
"elapsed_s": float(modal_best["elapsed_s"]),
"errors": int(modal_best["errors"]),
"num_runs": int(len(modal_df)),
"ran_at_utc": modal_best["ran_at_utc"],
},
]
).sort_values("best_req_per_s", ascending=False).reset_index(drop=True)
OUT_PATH = DATA_DIR / "benchmark_summary.csv"
summary_df.to_csv(OUT_PATH, index=False)
show_df(summary_df)
import matplotlib.pyplot as plt
import seaborn as sns
LABELS = {
"threadpool_single_host": "Thread Pool",
"asyncio_single_host": "Async (single client)",
"asyncio_sharded_single_host": "Async (sharded clients)",
"modal_asgi_autoscale": "Modal ASGI autoscale",
}
plot_df = summary_df.sort_values("best_req_per_s", ascending=True).reset_index(drop=True)
plot_df["label"] = plot_df["approach"].map(LABELS)
sns.set_theme(style="whitegrid")
fig, ax = plt.subplots(figsize=(8, 3.2))
colors = sns.color_palette("viridis", n_colors=len(plot_df))
bars = ax.barh(plot_df["label"], plot_df["best_req_per_s"], color=colors)
x_pad = plot_df["best_req_per_s"].max() * 0.02
for i, bar in enumerate(bars):
value = bar.get_width()
n_items = int(plot_df.loc[i, "num_items"])
ax.text(
value + x_pad,
bar.get_y() + bar.get_height() / 2,
f"{value:.1f} req/s (n={n_items})",
va="center",
ha="left",
fontsize=10,
)
ax.set_xlabel("requests / second")
ax.set_ylabel("")
ax.set_title("OpenAI Throughput by Approach (best run per approach)")
ax.set_xlim(right=plot_df["best_req_per_s"].max() * 1.35)
sns.despine(left=True, bottom=True)
plt.tight_layout()
Takeaways
- A single host with plain async can be very strong.
- Sharded single-host async can push higher before moving to more infrastructure.
- Modal ASGI adds easy horizontal scale and cleaner operational isolation.
- Modal makes it so easy to deploy a FastAPI service that it's hard to justify not using it for scaling out throughput.
- Counterintuitively,
max_inputs=1gave higher throughput thanmax_inputs>1for this batched workload. Each request already fans out many async OpenAI calls, so allowing multiple requests per container created contention inside a single event loop. One batch per container plus horizontal autoscaling produced better overall throughput.